NLP Highlights at NeurIPS 2019
on Nlp, Neurips, Deep learning, Neurips2019
NeurIPS conference is usually less populated by NLP people ¯_(ツ)_/¯
But since some of us, including me, happened to get there in 2019, I want to make a review post and highlight the main works that were devoted specifically to working with the natural language.

Main NLP works can be divided into the following categories:
- Everything with Embeddings
- Reasoning and Modelling Brain
- New Architectures
- Finally Officially Released
- Demos
Yes, the categorization is quite Borgesian, who cares, let’s dive in!
Everything with Embeddings
On the Downstream Performance of Compressed Word Embeddings
The paper presents an approach similar to the direction of the distillation of models, in particular, BERT. Researchers at Stanford solved the same problem as everyone else — although embeddings are extremely effective, they demand a lot of memory and work slowly.
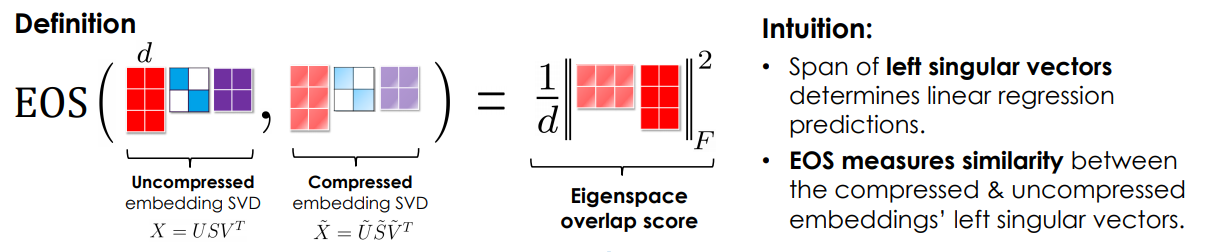
The idea is not to learn a smaller model but to find new ways to effectively compress the weights of ready-made models, and develop metrics that would show how well the compression went.
Models in concern — word2vec, fasttext и BERT, for the last all word vectors were taken from the vocabulary, being non-contextual.
Compression model: SVD + Eigenspace Overlap Score (EOS)
A correlation of word vectors in a bigger model and in a compressed one is proposed as a metric of compression quality. The results show that the proposed compression method allows reproducing 91% of the results for Fasttext and 92% of the BERT results.
Spherical Text Embedding
Text embeddings are widely used and show excellent results on many NLP tasks. However, they are usually trained within the Euclidean space, while their use is usually the calculation of cosine proximity, clustering (that is, typical application tasks: word similarity and document clustering). That is, the training phase and the use phase occur as if in different planes, while if you teach spherical embeddings right away, then the quality should become better.
As a result, a spherical generative model is proposed, where the word level and paragraph level embeddings are trained together. To train text embeddings in a spherical space, the authors developed an effective convergence optimization algorithm based on Riemannian optimization. The resulting model is highly efficient and achieves high results and even beats BERT somewhere (for example, just in the task of clustering documents).
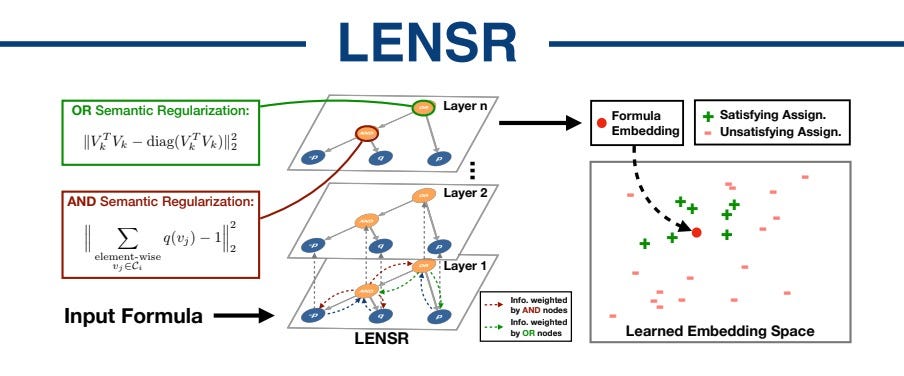
Embedding Symbolic Knowledge into Deep Networks
The authors proposed a network of logical embeddings with semantic regularization (LENSR), which encodes previous knowledge at the symbol level, which allows improving the quality and performance of deep models. LENSR is a graph embedding network that projects propositional formulas onto a distribution through an extended graph convolution network (GCN). To create semantically correct embeddings, the authors developed methods for recognizing node heterogeneity and semantic regularization, which adds structural constraints to embeddings.
The authors compared the quality of the various embeddings of logical representations: 1) General form 2) Conjunctive Normal Form (CNF). 3) Deterministic Decomposable Negation Normal Form (d-DNNF)
LENSR is effective for entailment (synthetic dataset) and visual relationship prediction (VRD dataset) tasks.
Interestingly, there is a connection between the theory of propositions and the simplification of embeddings. Further study of this relationship may clarify the relationship between compiling knowledge and teaching vector representation.
Reasoning and Modelling Brain
Interpreting and improving natural-language processing (in machines) with natural language-processing (in the brain)
Interesting interdisciplinary work at the junction of neuroscience and NLP (all about understanding how the brain works, you can better understand what happens in artificial networks). The authors proposed the following approach — they used recordings of the brain activity of subjects who read a narrative text, and based on this interpreted various representations obtained from neural networks such as BERT, XLNet.
Some results:
- Transformer models (BERT and Transformer-XL) capture the most important contextual information for the brain in their middle layers of the network
- Transformer-XL combines both the properties of the transformer and the recurrence properties, which prevents loss of quality even in very long contexts, in contrast to purely recurrent models or purely transformers.
- Consistent focus on shallow layers in BERT actually improves both brain predictions and NLP syntax performance
Next steps: to get more informative conceptual signs from brain MRI, which would contain specific conceptual information and understanding which area of the brain is responsible for what; use this further to study how semantic information is represented in networks.
Quantum Embedding of Knowledge for Reasoning
A qualitatively new approach to the transfer of symbolic knowledge bases into a vector space that uses quantum logic (Birkhoff and von Neumann’s concept of 1936). Each type of relationship becomes its own axis in this space. Complications arise with logical relationships (conjunction and disjunction operators), but the authors of the article managed to show their implementation.
The result of application for the communication prediction problem is (Hit @ 1 = 0.96) (previous record 0.74). Unfortunately, there is a negative side to the question: if the previous algorithm, even if it did not get the first result, it was highly likely to hit the top ten — Hit@10=0.89. Quantum embeddings do not have this property: if the correct answer is not the first, then the probability of getting into the top ten is zero.
Learning by Abstraction: The Neural State Machine
The work is devoted to the creation of a finite state machine that would connect computer vision and text processing, but not of the ordinary text of a natural language, but of the “mental language” — an unambiguous language for describing objects and thinking (fictional abstraction).
The idea is dictated by the works of the largest philosophers and theorists of the language — Chomsky, Wittgenstein. But the implementation is extremely superficial — de facto simply sets of attributes of each item from the dictionary are taken:
- Item — Color
- Item — Size
- Item — Form
As well as signs characteristic of certain types of objects — poses, conditions, etc.
We then use these natural attributes of objects to build from them the embedding of the object. We build embedding based on feature vectors, and not on contexts in the corpus of texts.
Further, all this is transferred to the architecture of the neural network finite state machine with attention, which receives recognized objects from the picture and the question and learns to predict the answer.
As a result, we get the ability to answer tricky questions about what is happening in the pictures. + SOTA increase from 3 to 10% on various test datasets.

New Architectures
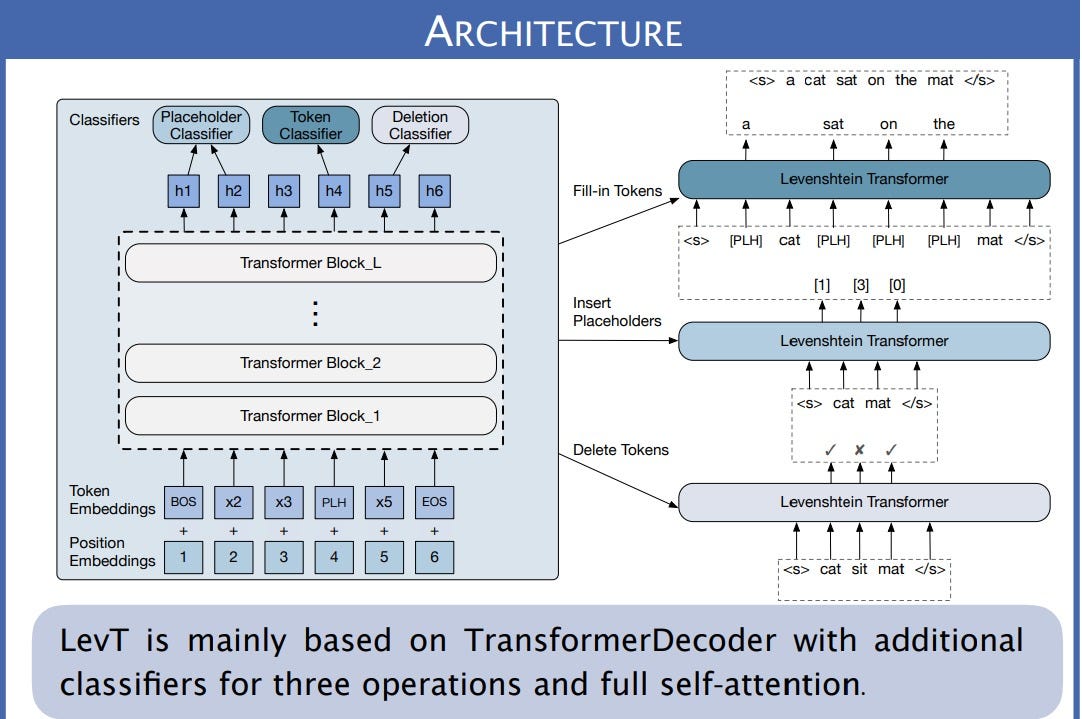
Levenshtein Transformer
A new attempt at transformers based on classic edit-distance steps. The attention block was removed from the transformer and replaced with the Levenshtein block (actions: replace / delete / insert)
Ordered Memory
Microsoft’s new neuron architecture, which is likely to replace the most popular recurrent architectures.
Motivation — Recent research shows that recursive, consistent memorization of characters and words in a text is critical to the generalizing ability of AI.
Moreover, in many languages (including English and Russian), you need to remember a fairly large context, since the syntax tree in these languages can have connected words very far from each other.
The new architecture handles long contexts and graph structures much better than LSTM, including through the attention mechanism and sequentially weighting each new character / word in a sequence.
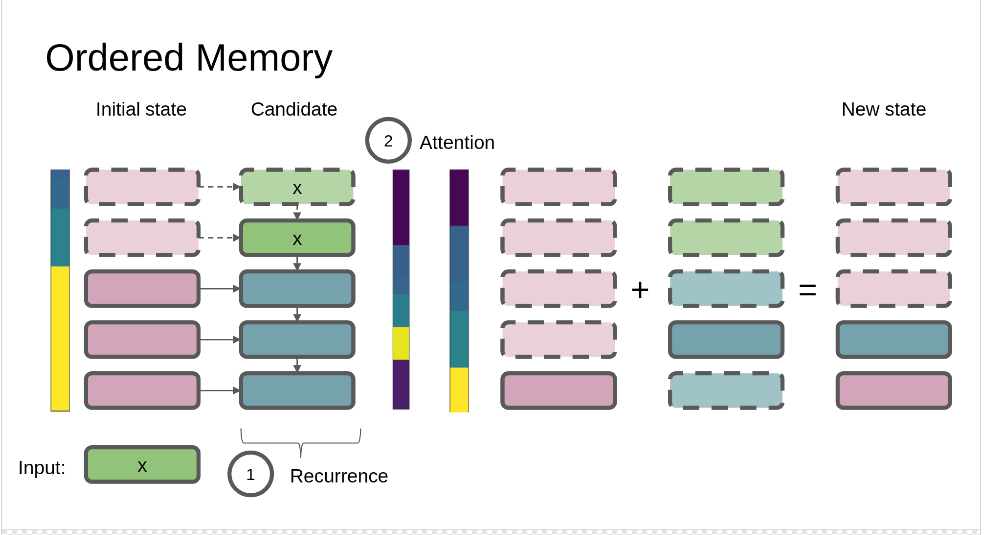
On existing datasets on which you want to restore information about a language sequence or tree, the architecture has achieved significant accuracy
- ListOps — 99.7% accuracy
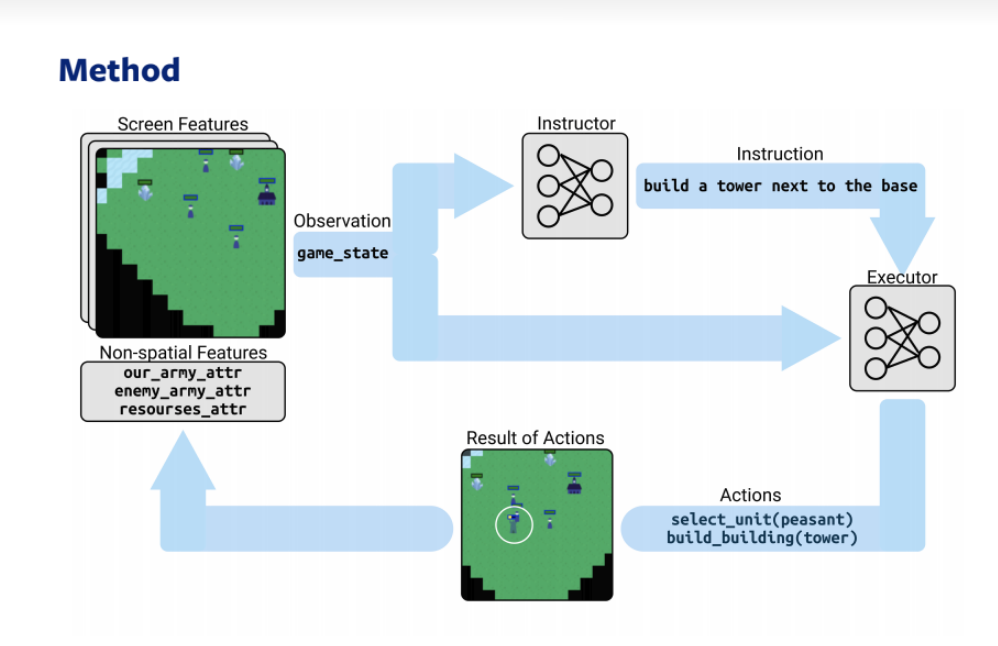
Hierarchical Decision Making by Generating and Following Natural Language Instructions
The work is dedicated to teaching the best strategies in an online game based on the instructions that users give each other.
The data from the interactions of user pairs is used:
- Strategist — decides what action to take immediately: put the peasants on the field, build a castle, start a war with a distant castle, etc.
- Executor — receives a command from a strategist and performs actions that he considers necessary, including following instructions.
In an ideal situation for training a neural network, the executor performs only those actions that the strategist describes to him, although in reality this, of course, is not entirely true — the executor skips some commands and does a lot “on his own.”
Based on the statement (erroneous!) That the language is compositional, and the meaning of the team is made up of the meanings of individual words in the sentence, the researchers built an architecture that connects user actions on the field and messages received from the strategist.
The resulting architecture includes two subnets training together:
- Instructor — RNN Generative, accepts the screen state as an input, generates instructions — what to do next
- Executor — LSTM, accepts the screen state, instructions, history of previous states and instructions as input — selects the action that needs to be done.
As a result of the use of such a Joint architecture, the win rate and the ability to make both long-term and short-term decisions in strategic games (due to the memory of recurrent networks) are significantly increased.
Finally Officially Released
SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems
In recent years, many new pre-trained models have appeared, transfer lening shows amazing results on various NLU tasks, but there is no unambiguous reliable assessment of these models.
The GLUE benchmark presented a little over a year ago, offers a unique metric, which is an average score for 9 different classification problems (tonality analysis, paraphrase, etc.). However, recently the test assessment has exceeded the level of expert evaluation of people, which limits further research.
In the article, the authors present the SuperGLUE metric, a new benchmark developed in the GLUE style.
SuperGLUE Tasks:
- standardize assessment
- provide an unambiguous metric for NLU models
SuperGLUE — averaged evaluation on 8 NLU tasks:
- tasks are more diverse (for example, coreference, QA, etc.).
- selected tasks are hard to evaluate, hard to evaluate for machines, easy for humans
- selected tasks with a small data set for training
For SuperGLUE also available: ○ additional diagnostics ○ updated rules ○ start code
SuperGLUE is available at https://super.gluebenchmark.com and provides an open leaderboard for comparing models.
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Modern universal transformers have their pros and cons: Auto-regressive models (ELMo, GPT)
- Free of artificial noise in the data
- No bidirectional context
Denoising auto-encoding (BERT)
- Can make independent predictions
- Trained on noisy data with {mask}
- Have a natural context on the right and left
How to combine the advantages of both approaches? XLNET architecture — Permutation Language Modeling (PLM), combining autoregressive + bidirectional approaches
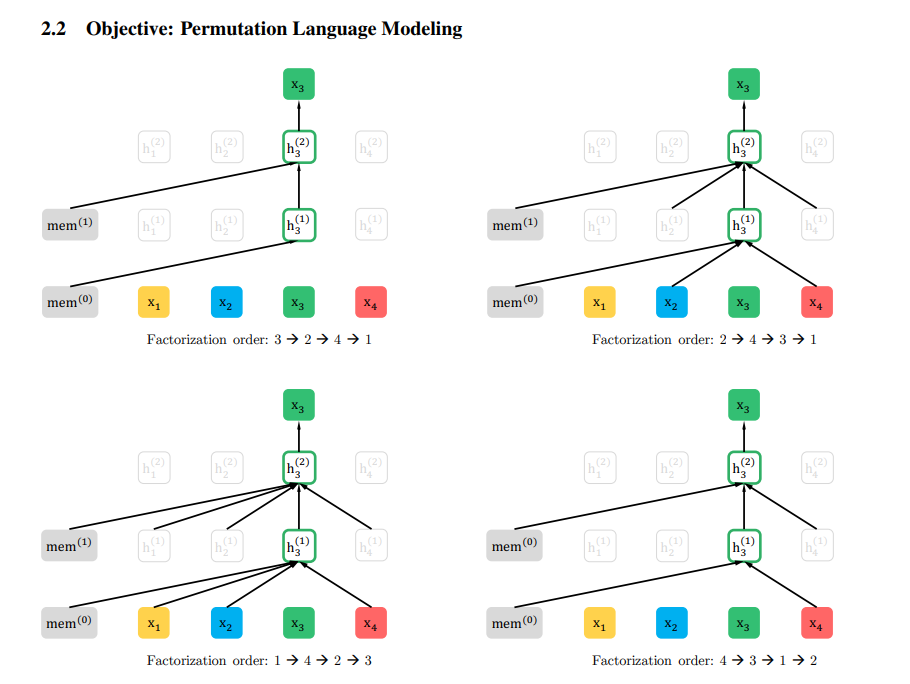
(we use all permutations of words in teaching a language model) Transformer XL built on segment-level recurrence + relative positional attention
Demos
AllenNLP Interpret: Explaining Predictions of NLP Models
Combining Transformer XL with PLM gives SOTA a GLUE result compared to other models, in particular BERT and RoBERTa.
The AllenNLP introduces a new tool for interactive interpretations of various NLP models.
This tool makes it easy to apply gradient significance maps and competitive attacks to new models, as well as develop new interpretation methods. The AllenNLP interpretation contains three components:
- set of interpretation methods applicable to most models
- API for developing new interpretation methods (for example, API for receiving input gradients)
- reusable web components to visualize results
Models available for interpretation: masking language models, sentiment analysis, SQuAD, Textual Entailment, NER and many others.
The system also allows you to upload your own models to pytorch in the same format and receive analysis and visualization.
exBERT: A Visual Analysis Tool to Explain BERT’s Learned Representations
Language models are a very powerful tool in NLP tasks that provides a contextual representation of a language. However, it is often difficult to understand what exactly the attention mechanism has learned, what specific information is encoded.
ExBERT is an interactive tool introduced by IBM that allows users to explore what and how the transformer learned in the process of creating a language model.
The tool works with the pre-trained base version of Bert. To understand what your architecture has learned, you need to submit a natural language offer as input, exBert will parse the offer into tokens suitable for BERT (BPE tokenizer) and feed the tokens into the model. Then the attenuations and subsequent embeddings for each encoder are extracted and displayed for interactive work with them. exBERT focuses specifically on self-attention, that is, the mechanism of attention of words in a sentence relative to other words in the same sentence.
To facilitate the interpretation of language parameters, several key BERT functions were disabled (masking was saved):
- attention for [CLS] and [SEP] disabled
- there is no functionality for exploring attention between different words
The authors advise working with the tool within a single sentence, despite the fact that BERT is able to analyze large pieces of a paragraph immediately.
Instead of an epilogue
Although NLP is not a very specialized topic at NeurIPS, it follows the same trends as AI in general. Join us in NLP, we have
- interpretation problems
- general models and their distillation
- and a big dream of recreating consciousness.
I will finally include here a keynote by Yoshua Bengio as being absolutely brilliant in blurring the boundaries between the technical component of machine learning and the theory of reasoning, capturing causality and obtaining systematic generalization in natural language processing.
And thanks for reading!
